本系列文章链接如下:
本系列文章主要介绍计算机系统中时钟的处理。主要内容包含NTP,Lamport逻辑时钟,向量时钟,TrueTime等。本文是第四篇,介绍TrueTime。
在本系列前面的文章中我们介绍过NTP协议,使用网络来同步真实世界的物理时间(Wall Clock)。由于广域网的复杂网络状况,误差可能在100毫秒级别。这么大的误差显然是不适合一些精确度要求高的应用,一种办法是抛弃物理时钟,使用逻辑时钟解决物理时钟不可靠的问题。另外一种办法是努力提高物理时钟的精度,将误差降到可以接受的范围。Google设计的TrueTime就是这种方案的代表。
TrueTime硬件
TrueTime由Google于2012年提出,用于Google的全球范围部署的数据库Spanner。TrueTime由时钟硬件和算法组成。其中时钟硬件由GPS时钟和原子钟组成。之所以使用这两种硬件的原因是因为这两种硬件的故障原因不一样,这样可以提高时钟的可靠性。GPS时钟故障的原因有天线和接收器故障,无线信号干扰等。原子钟可能由于频率问题造成时钟漂移。这两种原因是不相交的,所以能提高整个硬件的可靠性。整个硬件的成本并不贵,淘宝上原子钟的价格从几千到几万都有。下图是美国Symmetricom公司的超小型芯片级原子钟,价格1500美元。

TrueTime架构
TrueTime架构如下:
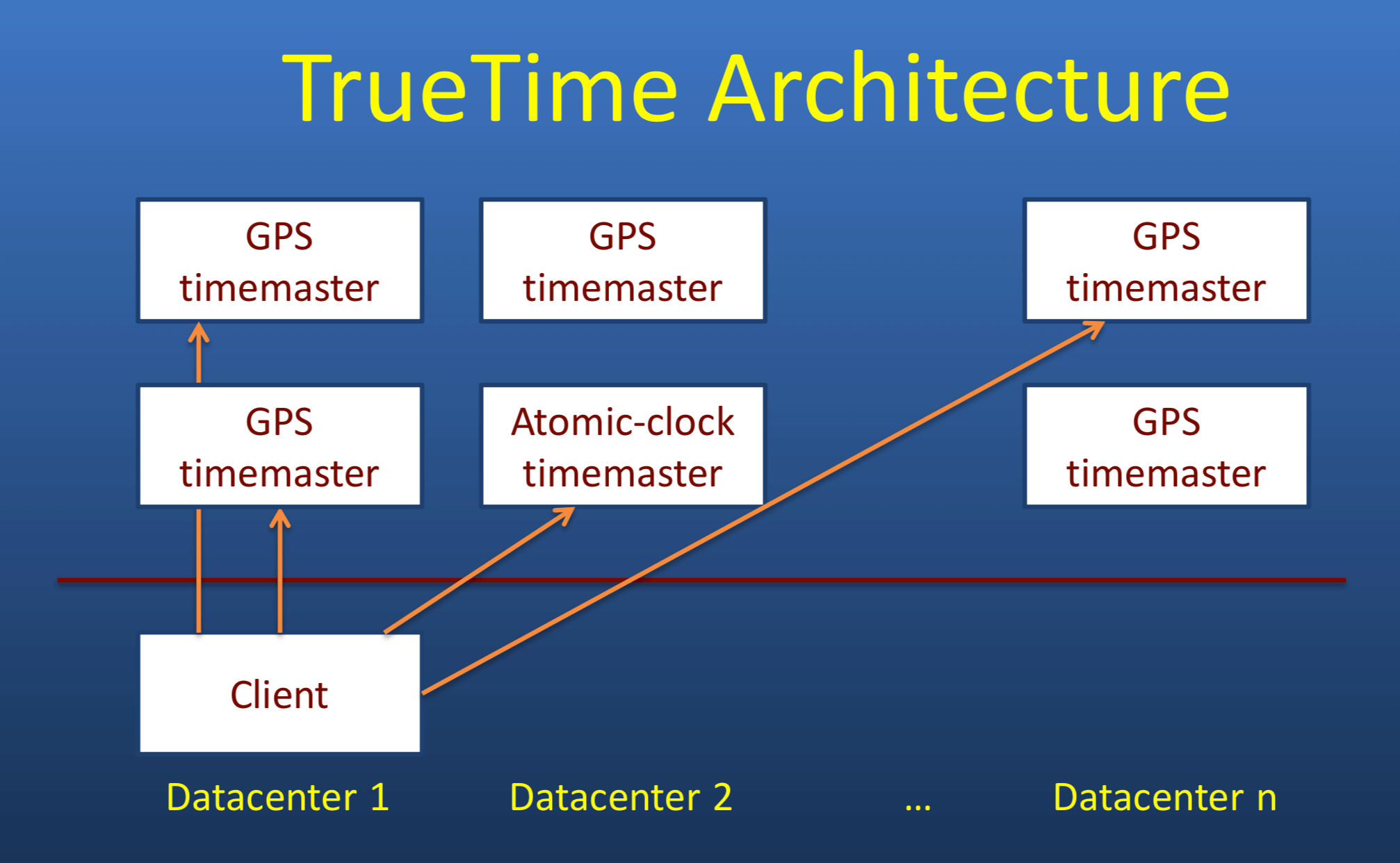
每个数据中心有若干个time master机器。大部分time master机器安装了GPS天线和接收器。剩下的time master机器安装了原子钟。time master之间会相互校验时间,如果某个time master发现自己的本地时间和其他time master相比差异很大,会把自己设置为离线,停止工作。客户端向多个time master查询,防止某个time master出现故障影响结果。
即使使用了GPS时钟和原子钟,也不能保证时钟0误差。2012年Spanner论文发表时,时钟的误差范围 ε 是1ms到7ms,平均4ms。前面我们介绍过NTP的误差在100ms级别,TrueTime的误差相比NTP大大减少了。
TrueTime API
TrueTime提供了三个API来操作时间:
| Method | Returns |
|---|---|
| TT.now() | TTinterval: [earliest, latest] |
| TT.after(t) | true if t has definitely passed |
| TT.before(t) | true if t has definitely not arrived |
- TT.now() 返回的是当前时间,由于时钟硬件误差的存在,这个当前时间存在一个不确定的范围(uncertainty time),也即一个范围 [earliest, latest],可以保证当前绝对时间一定在这个范围内,上面介绍过,这个间隔范围最大是7ms。
- TT.after(t) 判断传入的时间戳是否已经是过去的时间,也即 t < TT.now().earliest。
- TT.before(t) 判断传入的时间戳是否是未来的时间,也即 TT.now().latest < t。
使用TrueTime API时,需要搭配下面两个规则。
- Start: 提交事务Ti时,leader必须选择一个大于等于TT.now().latest的时间作为提交时间戳si。
- Commit Wait: leader必须等待TT.after(si)为true后才能提交数据,也即必须等待si的绝对时间过去了才能提交数据。
使用这两个规则可以保证:如果事务 T1 提交后 T2 才开始,那么 T2 的提交时间一定晚于 T1 的提交时间。也就是说事务的提交顺序一定和事务发生的绝对时间上的顺序一致。
TrueTime应用
有了TrueTime API和Start,Commit Wait规则,能解决什么问题呢,如何应用呢?
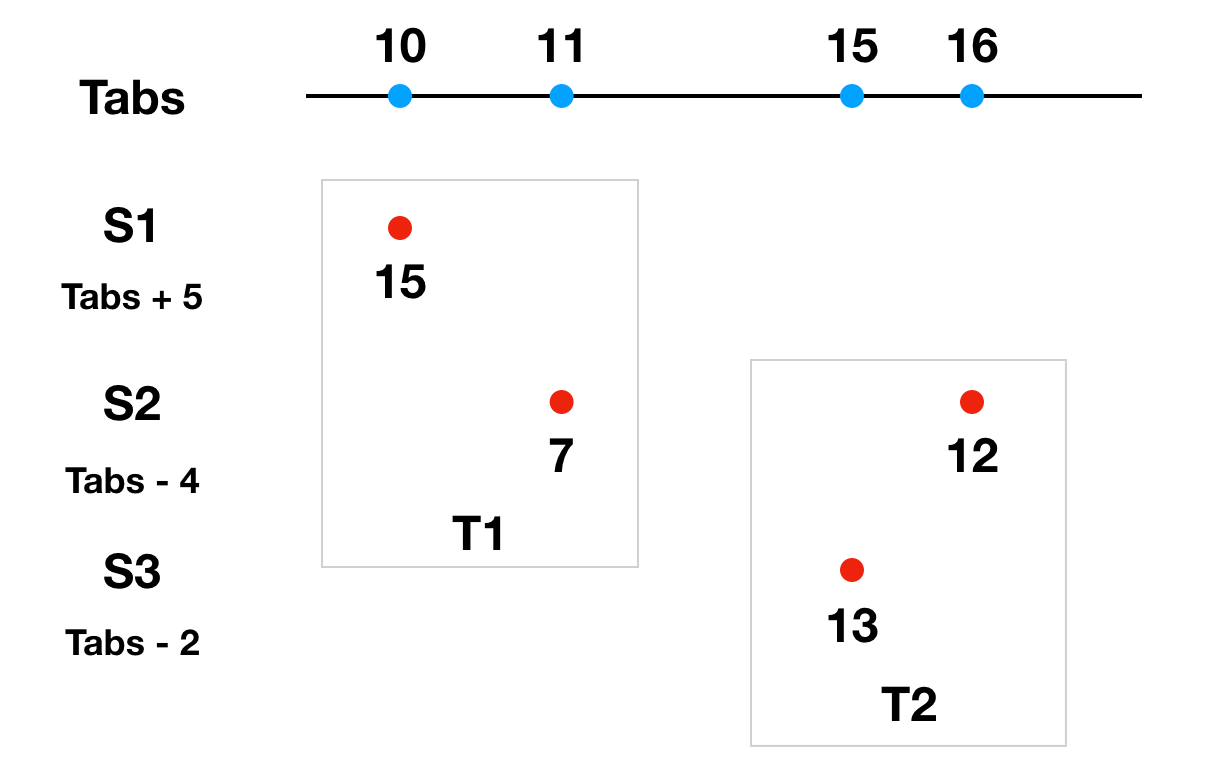
举个例子:分布式事务中有三台服务器S1,S2,S3。执行分布式事务时,某一台参与者作为协调者提交事务,提交时使用这次事务所有参与者中最大的时间戳作为事务的提交时间。每台服务器和绝对时间Tabs都有误差,S1的时间比绝对时间快5ms,即Tabs + 5,S2的时间比绝对时间慢4ms,即Tabs - 4,S3的时间比绝对时间慢2ms,即Tabs - 2。
现在有一个事务T1,参与者包括S1和S2,S1执行分支事务的本地时间是15ms,S2执行分支事务的本地时间是7ms。S2作为协调者,提交事务时选择了15ms作为整个事务的执行时间。
另外一个事务T2,参与者包括S2和S3,S3执行分支事务的本地时间是13ms,S2执行分支事务的本地时间是12ms。S2还是作为协调者,提交事务时选择了13ms作为整个事务的执行时间。
什么?绝对时间上事务T2比T1要晚执行,但是提交时间T2却比T1要早,这显然是错误的。
我们看看使用TrueTime如何解决这个问题。
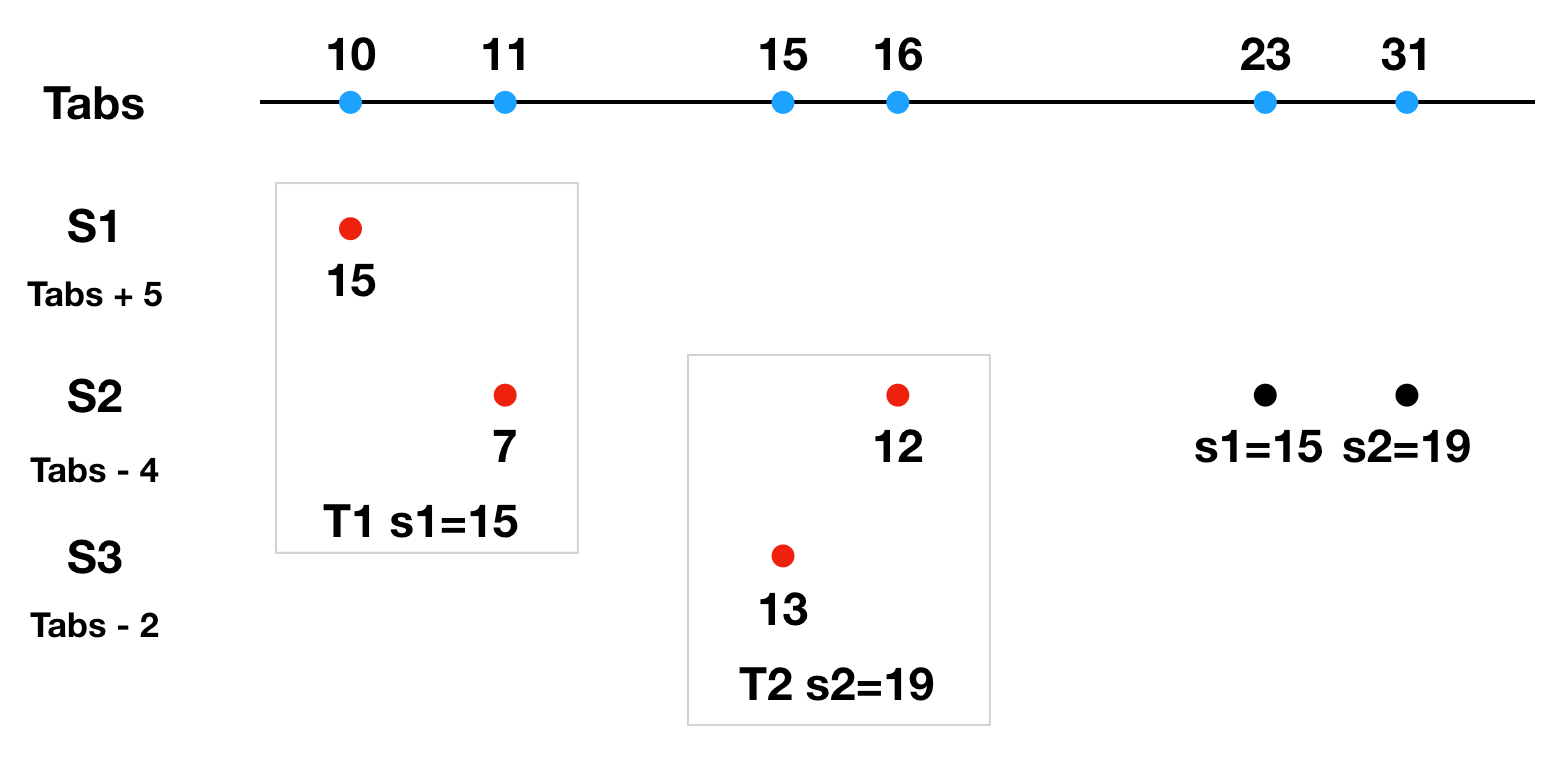
假设TrueTime误差 ε 为7ms。
T1事务协调者选择提交时间s1时,根据 Start 规则,必须大于所有事务参与者中最大的本地时间,还要大于协调者本地TT.now().lastest。计算得出 s1 = max(15, 7 + 7) = 15ms。
选择提交时间s1后,根据 Commit Wait 规则,还要等待TT.after(15)为true后才能提交数据。也就是TT.now() 是 [16, 30],S2的本地时间是23,绝对时间27ms提交数据。
T2事务协调者选择提交时间s2时,根据 Start 规则,计算得出 s2 = max(13, 12 + 7) = 19ms。
选择提交时间s2后,根据 Commit Wait 规则,还要等待TT.after(19)为true后才能提交数据。也就是TT.now() 是[20, 34],S2的本地时间是27,绝对时间31ms提交的数据。
可以看出T2的提交时间要晚于T1,解决了这个例子中的问题。当然,实际处理时,还会对数据进行加锁等操作,Google Spanner中详细的事务处理流程可以查看论文。
TrueTime性能
Google Spanner中,对同一个数据进行修改时,需要加锁,TrueTime相当于是把所有并发操作串行化,进行排队。由于TrueTime的误差在1到7ms之间,平均误差4ms。一次事务需要等待两个 ε,一个是选择提交时间时需要等待TT.now().latest,另外一个是提交数据时需要等待TT.after(s),平均需要等待8ms。也就是说对于同一个数据的写事务,Spanner并发量是每秒125个。这是论文发表时的数据,论文中也写到未来希望把误差 ε 降低到1ms。
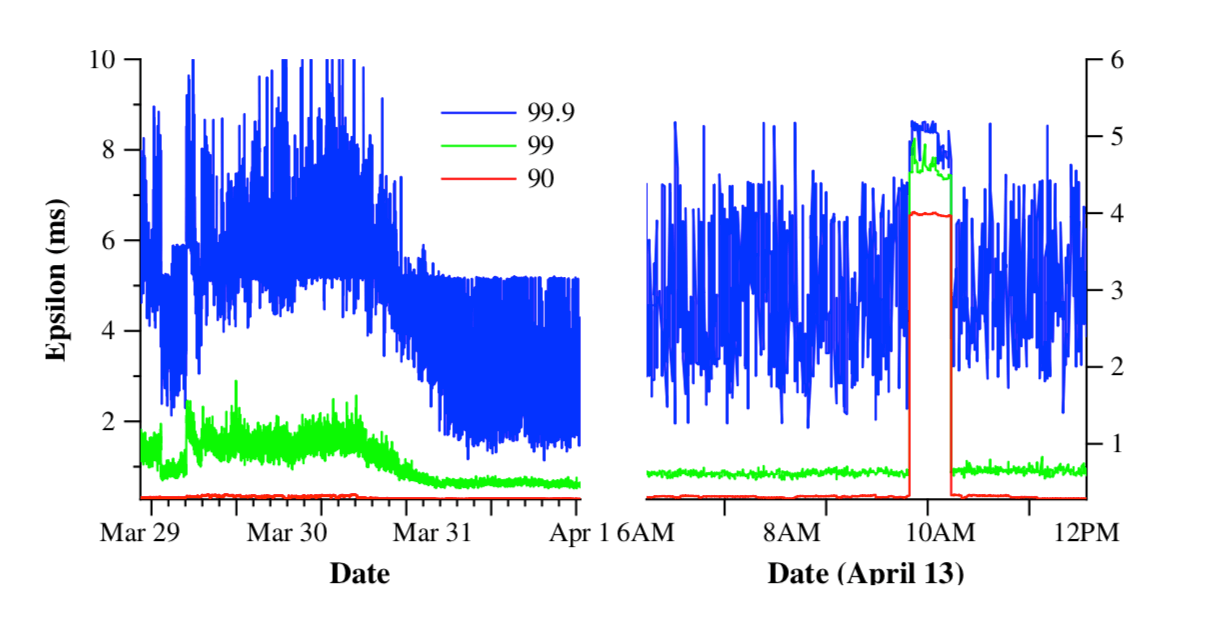
上图是论文中给出的误差 ε 数据,从中可以看到,90%的误差 ε 都在1ms以内,99%的误差 ε 都在2ms以内。
关于性能,论文中有句话我深以为然:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
参考
Spanner: Google’s Globally-Distributed Database