问题描述
考虑这样一个问题,一个分布式流处理系统,比如Flink,数据源源不断地从输入端涌入,系统中多个任务进程对数据进行各种计算,比如对某个数据进行求和,然后把处理后的数据结果发送给其他任务进程继续处理。系统中的任务进程是有状态的,比如数据求和的临时结果。如何对这样的系统保存全局快照,以应对系统崩溃等问题?
直观的方法有两种,这两种方法都会”stop the world”。一种是让所有任务进程约定同一个时间点保存自身状态。然而我们知道系统时间无法做到完全同步,没法精确地让所有任务进程同时保存自身状态。另一种方法是让中心管理进程给所有任务进程发一个控制指令,所有任务进程停止处理新的数据,保存自己的状态。这种方式会中断整个系统的运行,显然不是我们想要的方案。而且这种方案会导致另外一个问题,那就是数据可能不一致。举个例子:
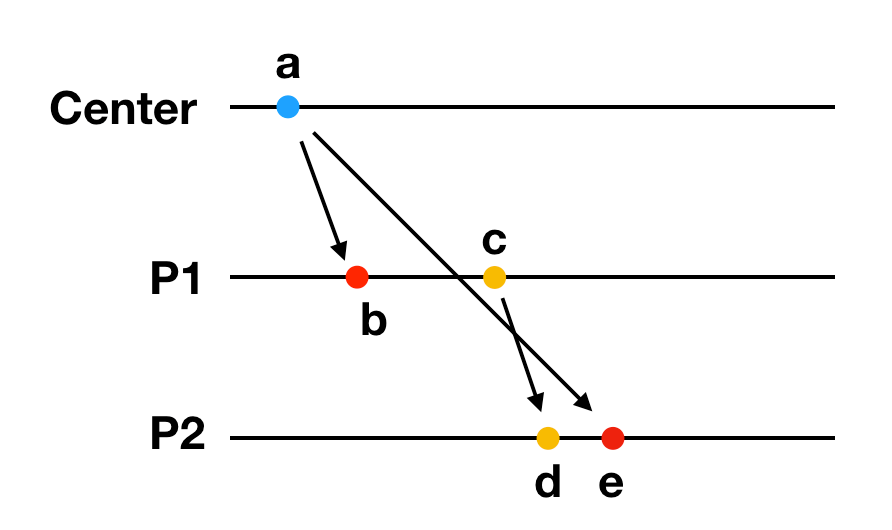
一个中心进程和两个任务进程P1, P2组成的分布式系统,P1和P2进程会相互发送应用层面的消息。中心进程在a时刻给两个任务进程分别发送了保存状态指令,P1进程先收到了指令,保存了P1自身状态,然后继续处理业务,给P2进程发送了一个应用消息。P2进程在d时刻先收到P1发来的应用消息,之后在d时刻终于收到了中心进程发来的保存状态指令,然后保存P2自身的状态。
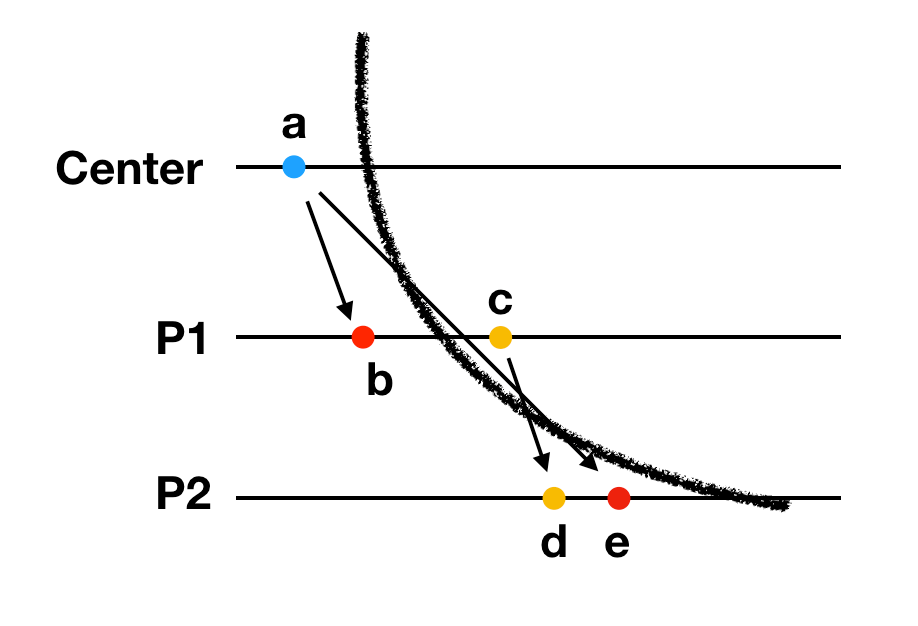
这次的全局快照对应着大号黑线所标识的横截面。横截面左边的事件在快照中,右边的事件不属于。d节点属于全局快照中,c节点不属于全局状态。然而c节点发生在d节点之前,这违法了一致性。也就是对于全局快照中保存的任何一个事件,在这个事件之前发生(happend before)的事件应该保存在这次的快照中。
Chandy-Lamport算法
对于这个问题,早在1985年就由我们的老朋友Leslie Lamport和K. Mani Chandy研究过了。两位老爷子有一天吃着火锅唱着歌,宿醉了一个晚上后第二天想出了一个算法,也被称作Chandy-Lamport算法。这个算法不会中断系统的正常运行,同时生成的快照符合一致性的要求。
前提条件
首先描述算法中的一些定义:
- 分布式系统由多个进程Pi组成。
- 每个进程通过网络通道和其他进程建立双向连接,Cij表示从Pi到Pj的连接通道,Cji表示从Pj到Pi的连接通道。
- 系统中的消息分为应用消息(application)和标记(marker)消息。应用消息是业务层面的消息,用M[xy]表示从x事件发到y事件的应用消息。标记消息是一种控制消息,用来生成快照。
这个算法有一些前提条件:
- 分布式系统中的进程不会崩溃。
- 进程之间的连接是保序的,也即FIFO Channel。
- 进程之间的消息是可靠传递的。
算法分为初始化、传播、结束三个步骤。
初始化
系统中任意一个进程Pi都可以发起快照请求。初始化的操作如下:
1
2
3
1. Pi记录自己的状态
2. Pi发送一条marker消息给所有其他进程
3. Pi记录所有其他进程发来的application消息
传播
对于任意一个进程Pj,如果从Ckj通道上收到了从Pk进程发过来的消息,分两种情况处理。
1
2
3
4
5
6
7
如果收到的消息是marker消息,并且第一次收到:
1. Pj记录自己的状态,把通道Ckj设置为空集合,不再记录Ckj上的消息。
2. 给所有其他进程发送marker消息,包括Pk。
3. 记录从其他通道Clj(l != k)上收到的application消息。
如果不是第一次收到marker消息:
把通道Ckj上记录的所有application消息作为通道Ckj的状态,不再记录之后发来的application消息。
为什么要给其他所有进程发marker,包括Pk?
给其他进程发送marker消息,目的就是告诉其他进程,在这条marker消息之后的application不用记录在这次的快照中。
结束
当以下条件满足时,整个快照流程结束:
1
2
1. 每个进程都收到了marker消息,并且记录了自己的状态。
2. 每个进程从每个通道中收到了marker消息,并且记录了通道的状态。
所有状态都记录完成后,可以由某个服务器收集这些分散的快照,形成全局快照。全局快照由每个进程的状态和每个通道的状态组成。这个收集过程就不详细讨论了。
示例
举个例子来描述这个算法,这样我们会更加清楚算法的流程。这个例子来源于Illinois University的Indranil Gupta教授的课程。
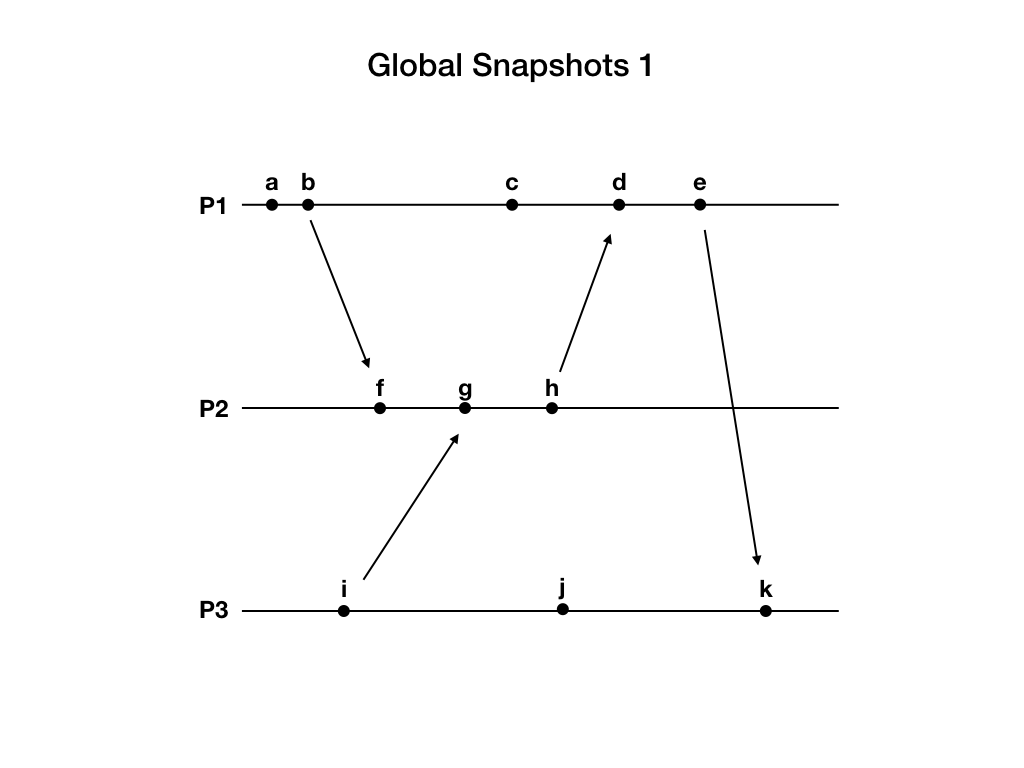
上图中分布式系统由三个进程P1, P2, P3组成。黑色节点是application事件,包括进程内的事件和网络消息。
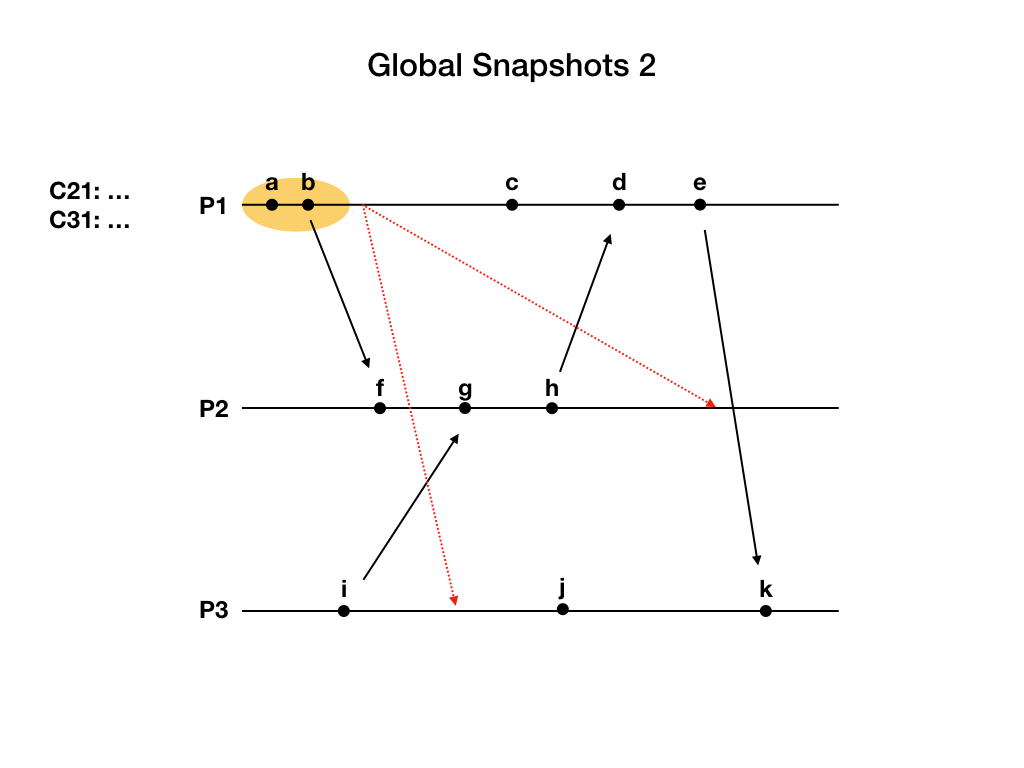
进程P1在b事件之后发起快照流程。P1首先记录自己的状态,这个状态包含a和b两个事件,然后给P2和P3发送marker消息,用图中红色虚线表示。之后开始记录从C21和C31通道发来的application消息。上图中用省略号表示正在记录这个通道的消息。
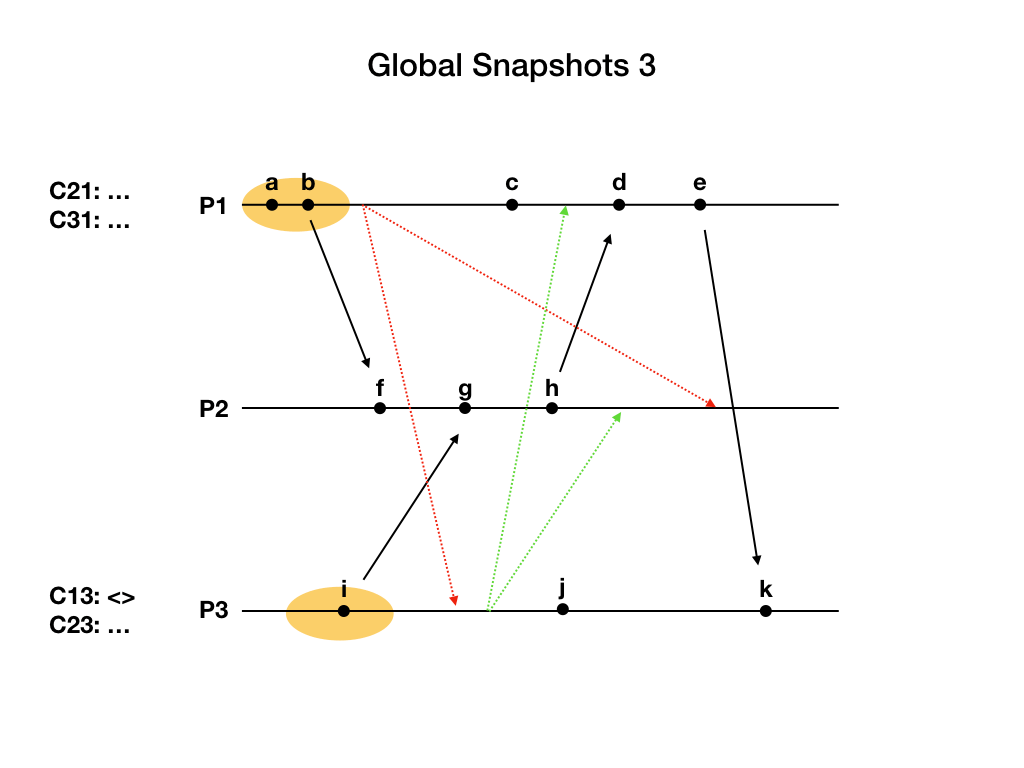
进程P3先收到marker消息,而且是第一次收到marker消息。P3记录自己的状态,包含i事件。然后设置通道C13为空集合。之后给P1和P2发送marker消息。最后开始记录C23通道发来的application消息。
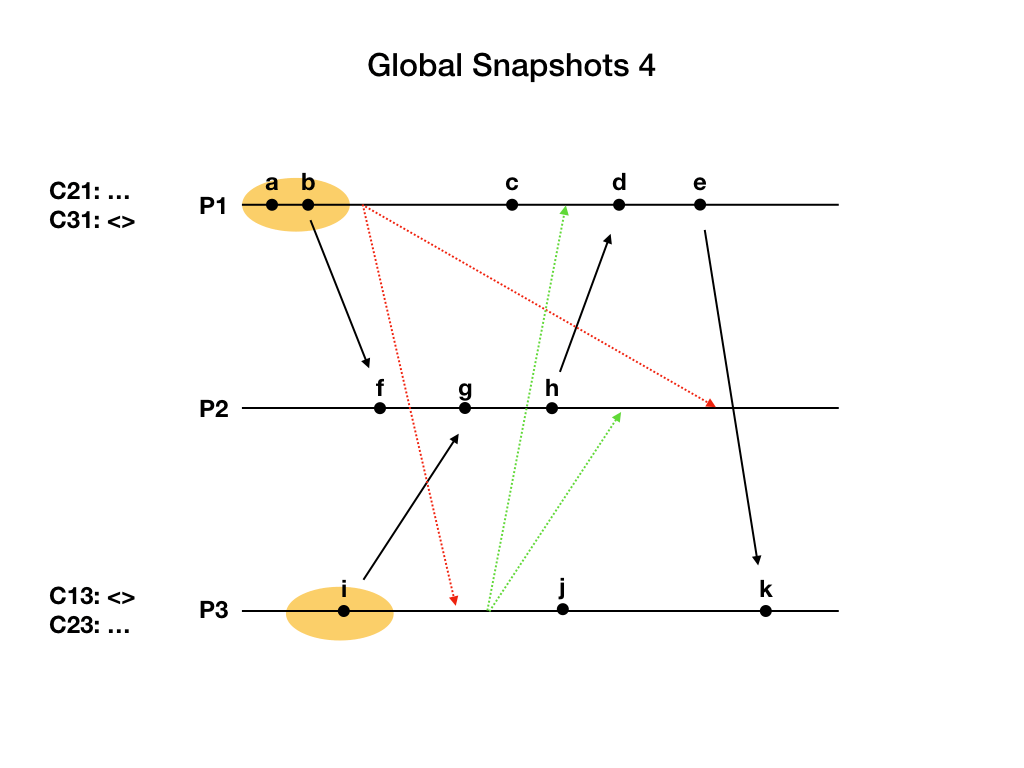
进程P1收到P3发来的marker消息,因为P1是这次快照流程的发起者,我们认为它已经收到过marker消息了,所以P1只需要把通道C31的状态设置为目前为止已经收到过的消息,也就是空集合。
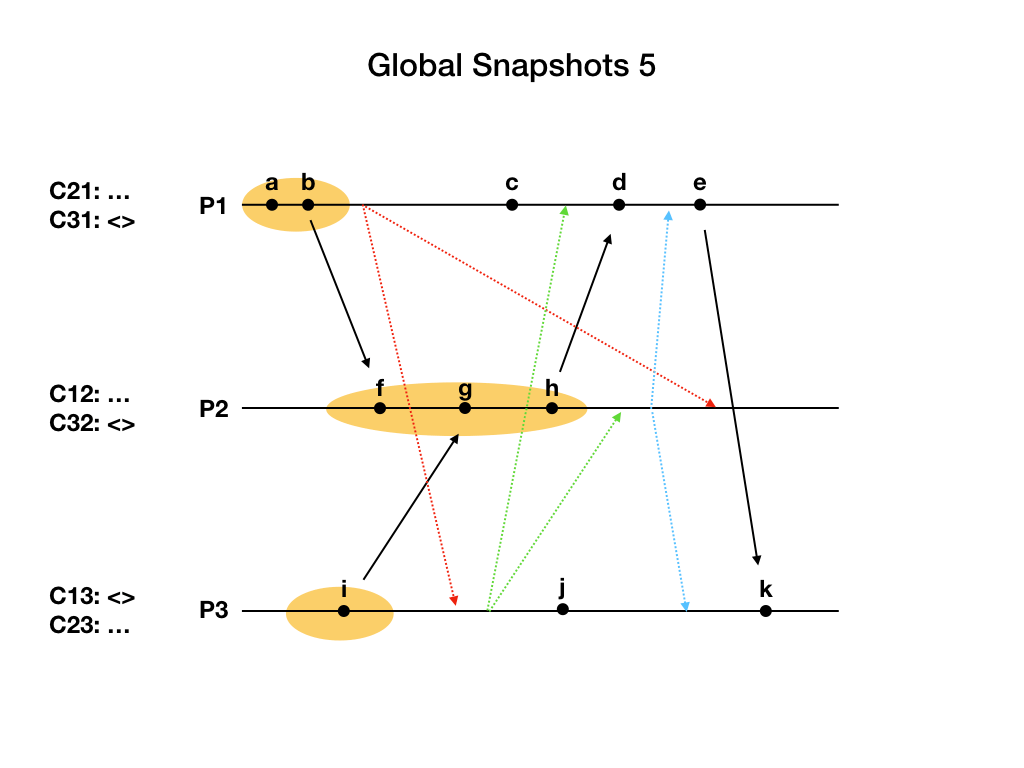
进程P2收到P3发来的marker消息,这是P2第一次收到marker消息。P2记录自己的状态,包含事件f, g, h。然后设置C32为空集合,之后给P1和P3发送marker消息,最后开始记录C12通道发来的application消息。
现在所有进程都已经记录了自己的状态,但是算法还没结束,因为通道的状态还没记录完。
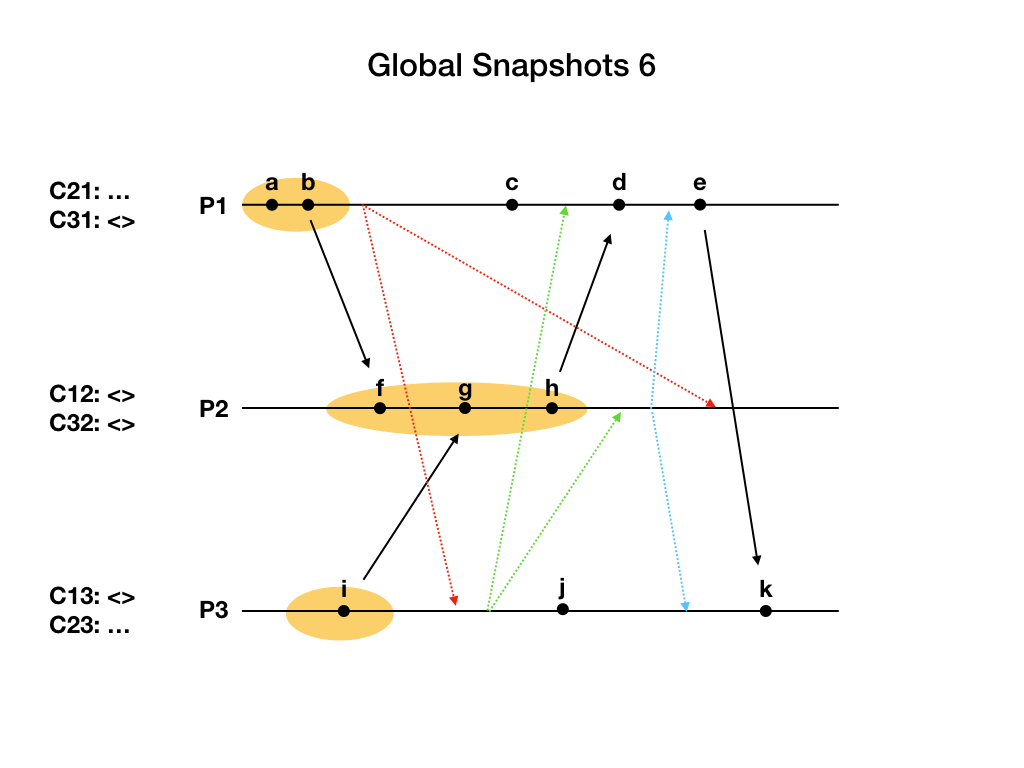
进程P2终于收到了P1发来的marker消息,把C12设置为空集合。此时P2从每个通道都收到了marker消息,它记录了自己的状态,和每个通道的状态,P2的工作完成了。
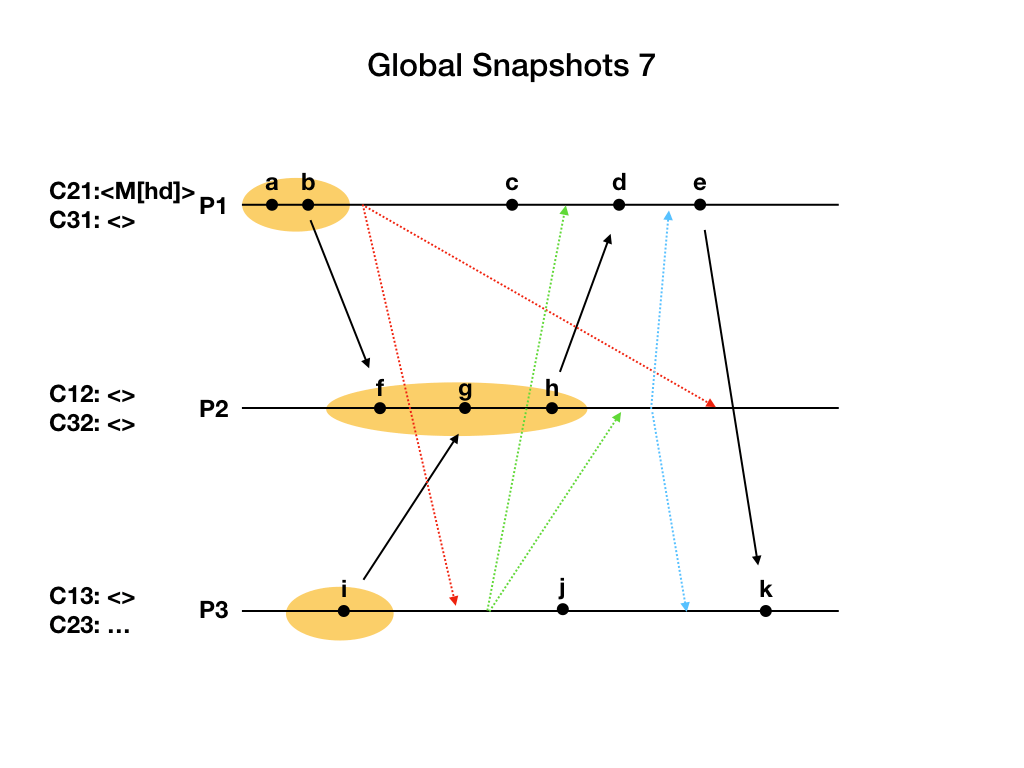
进程P1从通道C21上先收到进程P2在h事件发来的application消息,把这一消息M[hd]加到C21中。然后收到了P2发来的marker消息,结束通道C21的状态记录,包含M[hd]消息。P1完成了自己工作。
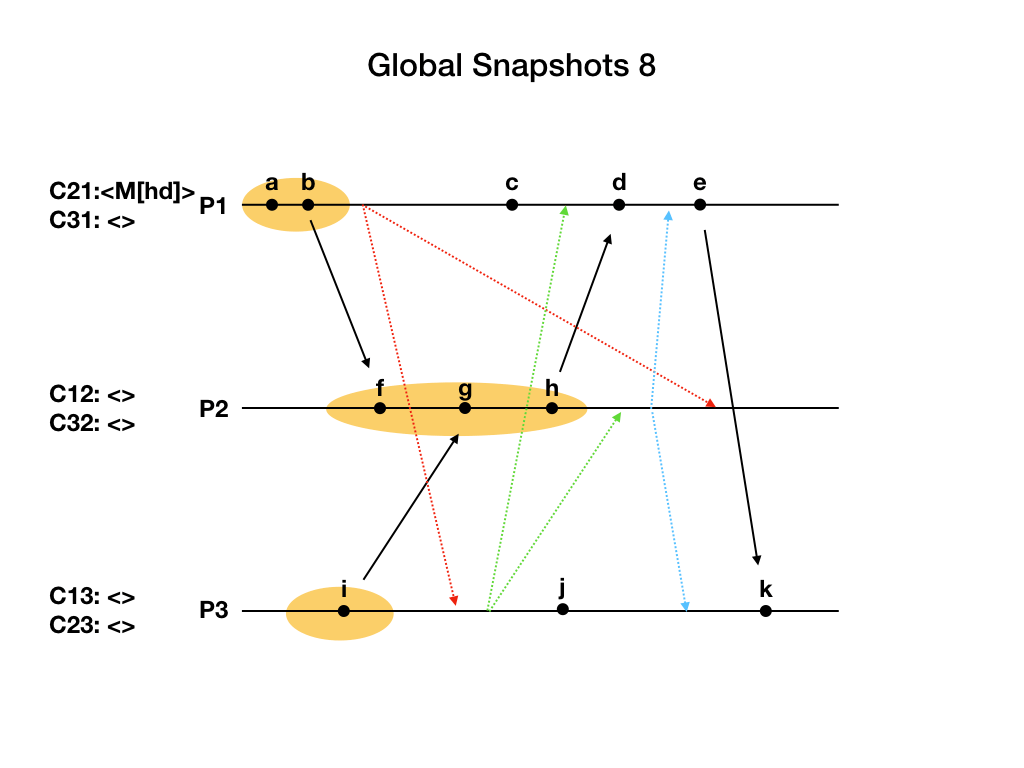
进程P3从通道C23上收到了marker消息。它也完成了自己的工作。
所有进程和所有通道的状态都记录完成,整个快照流程结束。
一致性切割 Consistent Cut
上文提到过一致性:对于全局快照中保存的任何一个事件,在这个事件之前发生(happend before)的事件应该保存在这次的快照中。这个也称因果一致性。
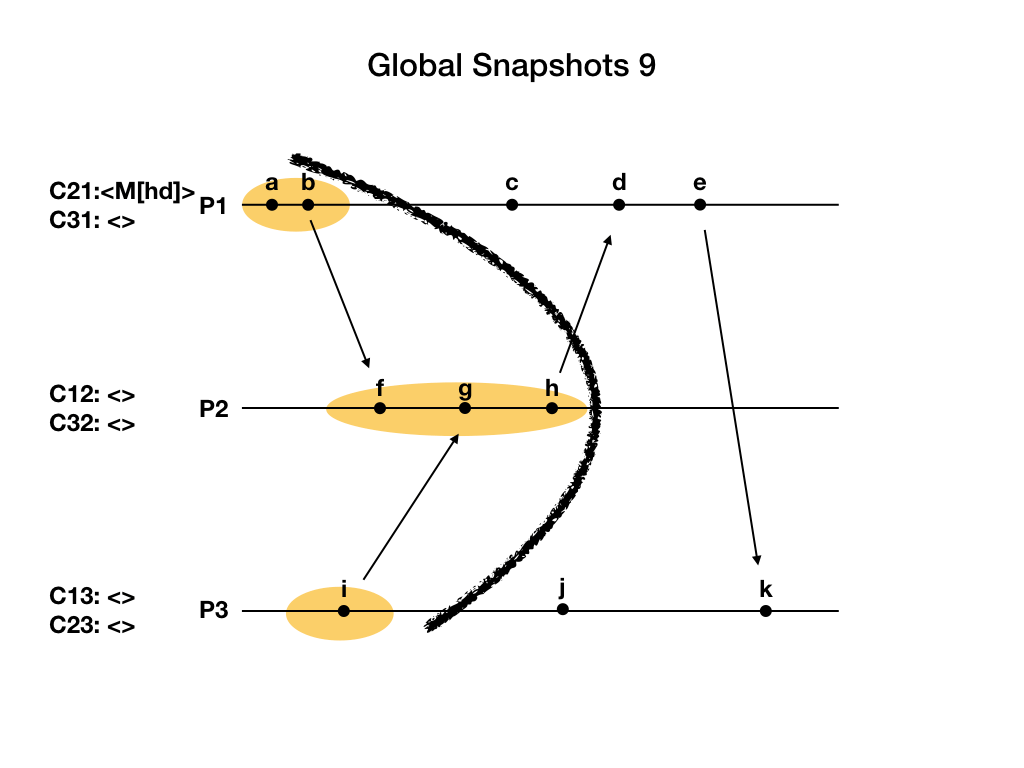
上个例子生成的快照是上图中大号黑线对应的横截面。黑线左边的事件都保存在快照中,属于过去发生的事件。黑线右边的事件都没有保存在快照中,属于未来发生的事件。Chandy-Lamport算法生成的快照满足一致性的要求,也叫做一致性切割(Consistent Cut)。
我们可以证明如果事件a happened before 事件b,b在快照中,那么a也在快照中:
如果a和b属于同一个进程内的事件,那么命题显然是正确的。
如果a是进程P的发送事件,b是进程Q的接收事件。因为b在快照中,那么进程Q肯定没有收到过marker消息,否则b事件不会在快照中。因为通道是可靠保序的,进程P肯定也没有发送过marker消息,所以a事件肯定也在快照中。
Flink的ABS算法
回到开篇的问题,Flink使用了一种称作Asynchronous Barrier Snapshotting(ABS)算法来生成全局快照。ABS算法在Chandy-Lamport算法基础上做了一些改动,通过阶段性地保存每个算子(operator)的状态,可以做到不需要保存通道的状态,但还是要求算子之间的连接是保序可靠的,而且算法会局部地停止处理数据。根据数据流中是否有环,ABS的处理方式有区别。
无环数据流
算法的流程如下:
- 中心协调者周期性地给所有输入源注入屏障barrier,也即Chandy-Lamport中的marker消息。输入源收到屏障barrier后,记录自己的状态,然后给所有的下游任务发送barrier。
- 中间任务节点从一个上游任务收到barrier,停止处理从这个上游任务发来的数据,其他上游任务的数据可以照常处理。
- 中间任务节点收到所有上游任务发来的barrier后,记录自己的状态,然后给所有下游任务发送barrier。
- 中间任务节点恢复处理所有上游任务发来的数据。
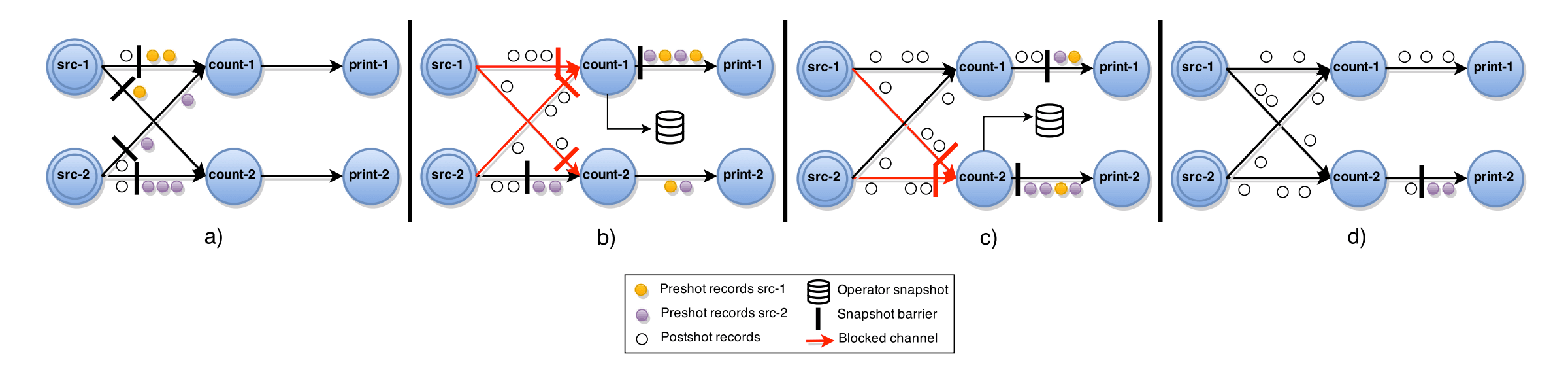
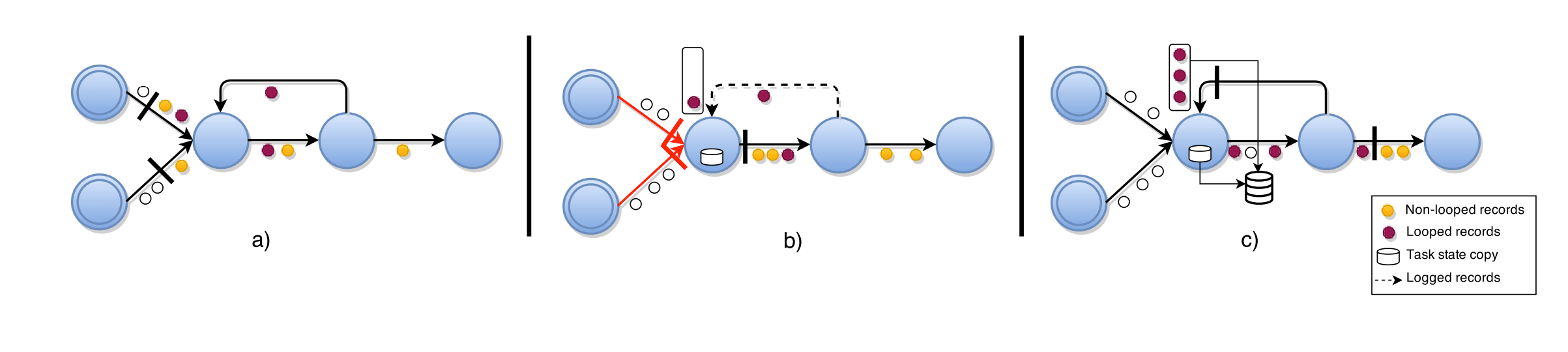
上图是ABS算法的一个实例。系统中由两个输入源任务,两个中间统计任务,两个输出打印任务组成。
图a)中两个输入源被中心协调者注入barrier,保存自身状态后分别给两个中间任务发送barrier。
图b)中count-1任务收到两个输入源发来的barrier后,停止处理两个上游数据,记录自身状态,往print-1任务发送barrier,然后恢复两个上游数据的处理。count-2任务先收到src-1输入源发来的barrier,然后停止处理src-1发来的后续数据,等待src-2发来的barrier。
图c)中count-2等到src-2的barrier也收到后,停止处理src-2发来的后续数据,记录自身状态,往print-2任务发送barrier,然后恢复两个上游数据的处理。
图d)中print-1已经收到了count-1发来的barrier,完成了本阶段的处理,print-2的barrier还在路途中。等到print-2处理完barrier后,整个快照流程结束。
有环数据流
对于有环数据流,不能简单地照搬无环数据流的算法,因为这样会造成有环节点因为等待环路上的barrier而造成死锁。
解决环的问题,首先需要标识出造成环路的那条边,称为back-edge,比如上图a)中连接中间两个任务的最上面的那条边。可以通过广度优先算法识别back-edge,如果一条边指向的终点已经遍历过了,这条边就是back-edge。
识别出back-edge后,任务节点在等待上游发来的barrier时,把back-edge先排除在外。收到所有其他上游发来的barrier后,先记录自身状态,然后给所有下游发送barrier,此时,任务节点需要记录从back-edge发来的数据,直到从back-edge也收到了barrier消息。全局快照中除了每个任务节点的状态外,还包含所有从back-edge收到的数据。有环数据流的示例如上图所示。
性能
《Lightweight Asynchronous Snapshots for Distributed Dataflows》 论文中给出了ABS的性能测试结果。
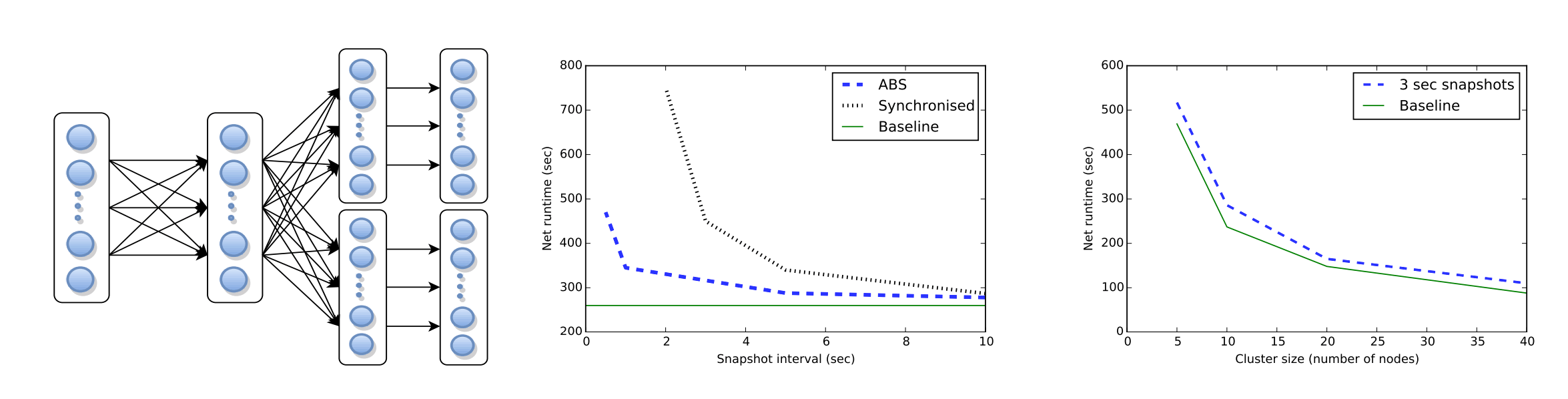
中间的图测试了ABS算法,同步算法(stop the world)和不执行任何快照算法这三种情况下的运行时开销。横坐标是快照间隔,纵坐标是运行时耗时。当快照间隔很小时,同步算法耗时比较多。这是因为同步会停止正常任务的执行,频繁快照时,这个耗时比较大。而ABS算法耗时要少很多。
右边的图测试不同集群大小下,ABS算法的耗时。随着集群数量的增加,ABS算法的耗时并没有大幅增长。
参考
Distributed Snapshots: Determining Global States of Distributed Systems
An example run of the Chandy-Lamport snapshot algorithm
Lightweight Asynchronous Snapshots for Distributed Dataflows