最近在看《Designing Data-Intensive Applications》,本文主要记录书中第五章《分区》的内容,加深自己的理解。
分区(Partitioning),也叫水平分割,是一种通过把不同用户分散到不同服务器上从而提升系统整体负载的方法。上一篇文章介绍过《复制》,有时分区和复制会混合使用,如下图所示,有4个分区,每个分区的数据有3个副本,而且3个副本在不同的物理机器上,这样可以防止一个副本所在的物理机器故障导致整个分区不可用的情况。
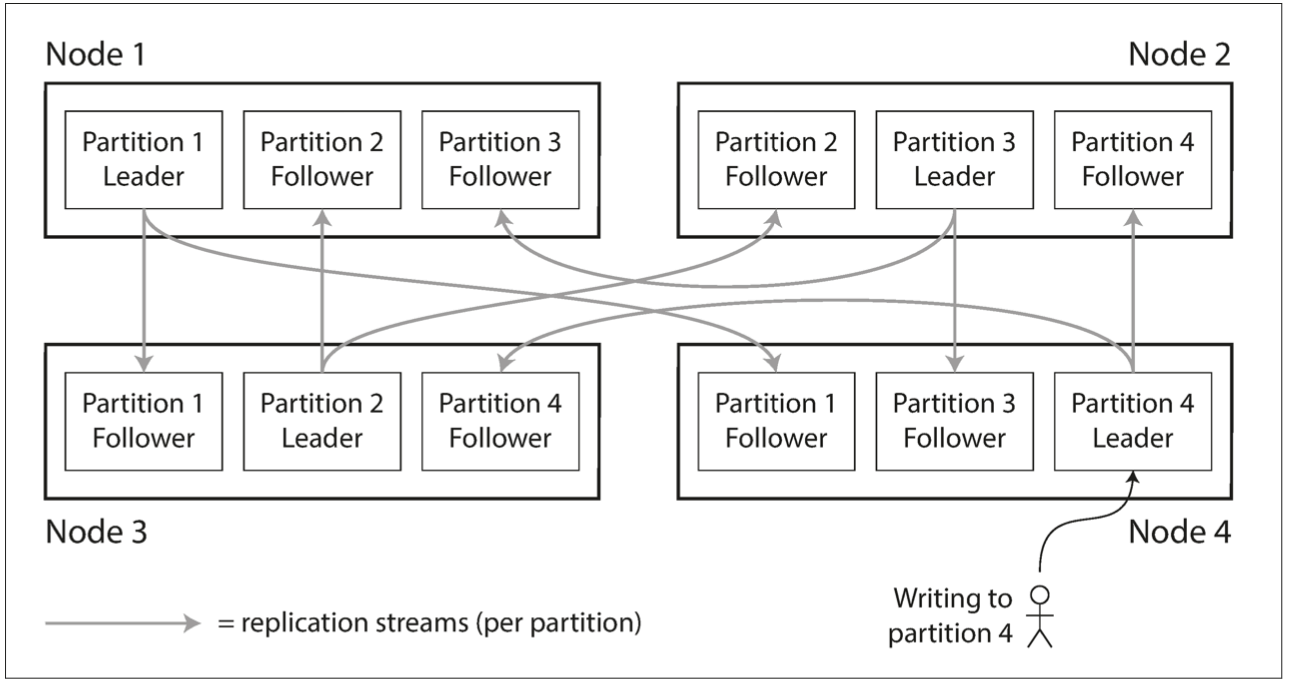
如何分区
按照关键字范围分区
第一种分区方法是按照关键字范围分区。比如按照用户ID划分,[0, 1000)属于第一个分区,[1000, 2000)属于第二个分区,以此类推。下图的百科全书按照字典顺序把条目分到了12本书中。
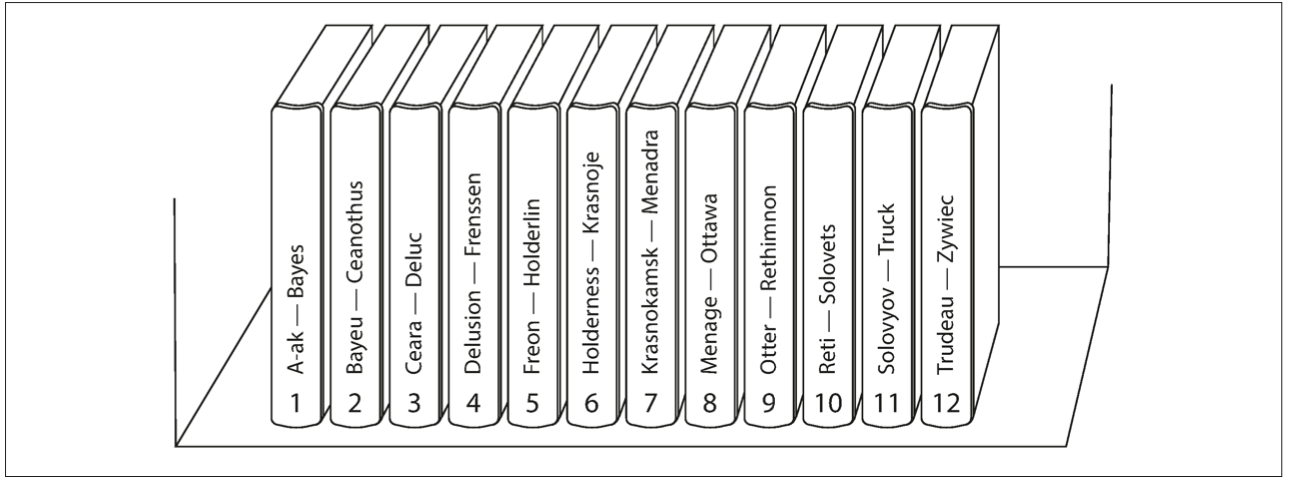
这种方式的优点是范围查询比较方便,因为相邻的ID在同一个分区。
缺点是可能出现分布不均匀的情况,造成性能热点。比如以时间作为key,写入使用当前时间,往往会落入同一个分区。查询往往查询最近几天的数据,也会落入同一个分区。再比如按照用户ID划分的游戏服务器,开服时用户落在第一个分区,满了后再开第二个分区,这时前面几个分区是性能热点,过了一段时间,老的用户可能流失了,前面几个分区可能没什么访问量了,此时又要合并分区。
按照哈希分区
第二种方式是按照哈希分区。一种想当然的方案是 hash(id) % server_count,这种方案有个问题是如果服务器数量变了,每个id很可能会落在不同的服务器上,这会造成所有用户数据从旧分区迁移到新分区。正确的做法是对哈希的结果再分段,比如哈希结果的[0, 1000)属于第一个分区,[1000, 2000)属于第二个分区。示例图如下所示,取每个key的前两个字节计算md5,把结果按照范围划分到8个分区中:

这种方式的优点是数据分布比较均匀,不容易产生性能热点。在实现的时候,为了让数据更加均匀,可以给每个服务器分配多个虚拟节点,每个虚拟节点负责一段范围,具体可以参考一致性哈希。
缺点是没法进行范围查询,因为相邻的ID很难在同一个分区。一种折中方案是用key的一部分去计算hash得出分区,其余部分在分区内顺序存储。比如Cassandra设计了一个复合主键(compound primary key),由多个列组成。其中第一列用于计算hash,其余列是按顺序保存在SSTable中。虽然对于不同的第一列值无法做范围查询,但是同一个key的其余列可以做范围查询。这种方式适合社交网站,一个用户发的帖子复合主键是(user_id, update_timestamp),可以按照时间范围查询同一个用户的帖子。
即使使用哈希方式,还是可能会遇到性能热点。比如微博,某个明星发了个帖子,可能有上百万的访问量和评论,这样还是会落在同一个分区上。一种解决方法是针对这个key再额外增加两个随机数字,这个key的评论进一步划分到100个分区上,减少热点。代价是查询的时候需要向这100个分区发送请求,合并后才能得到总数据。
二级索引
上文介绍的分区方法都是在主键(关键字)基础上进行分区,如果业务用到了二级索引(secondary index),如何处理?举个例子:一个卖二手车的网站,DB中主键是唯一ID,数据包含车的颜色、品牌和位置。如果要查询所有颜色是红色的车,如何实现?有两种方式,这两种方式都需要建立二级索引,也就是查询的列和主键的映射关系,区别在于二级索引的划分方式不一样。
二级索引按照主键分区
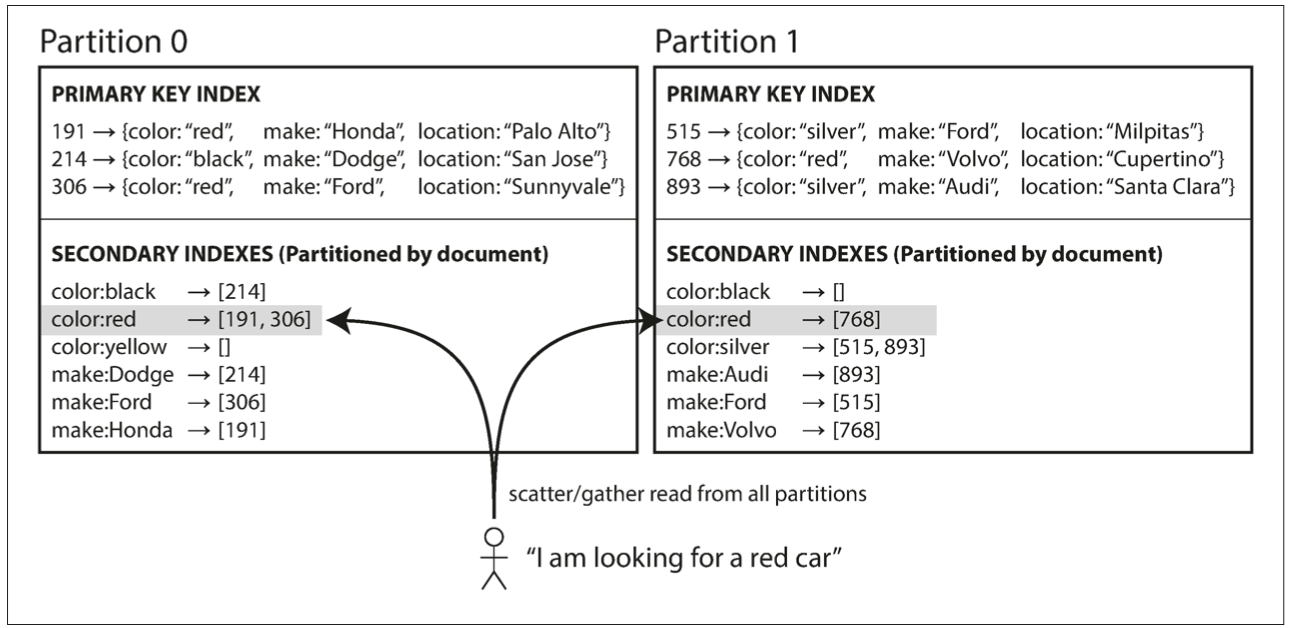
第一种方式是建立color和主键的映射关系,而且这种映射关系保存在每个分区内部,只保留本分区的数据。比如上图中,分区0中红色的车有191和306两个,都是分区0中的数据;分区1中红色的车有768,是分区1中的数据,不会有分区0中的数据。
这种方式查询二级索引需要把请求发到所有分区,因为每个分区都可能有对应的数据,比如每个分区中都有红色的车。
二级索引按照其他键分区
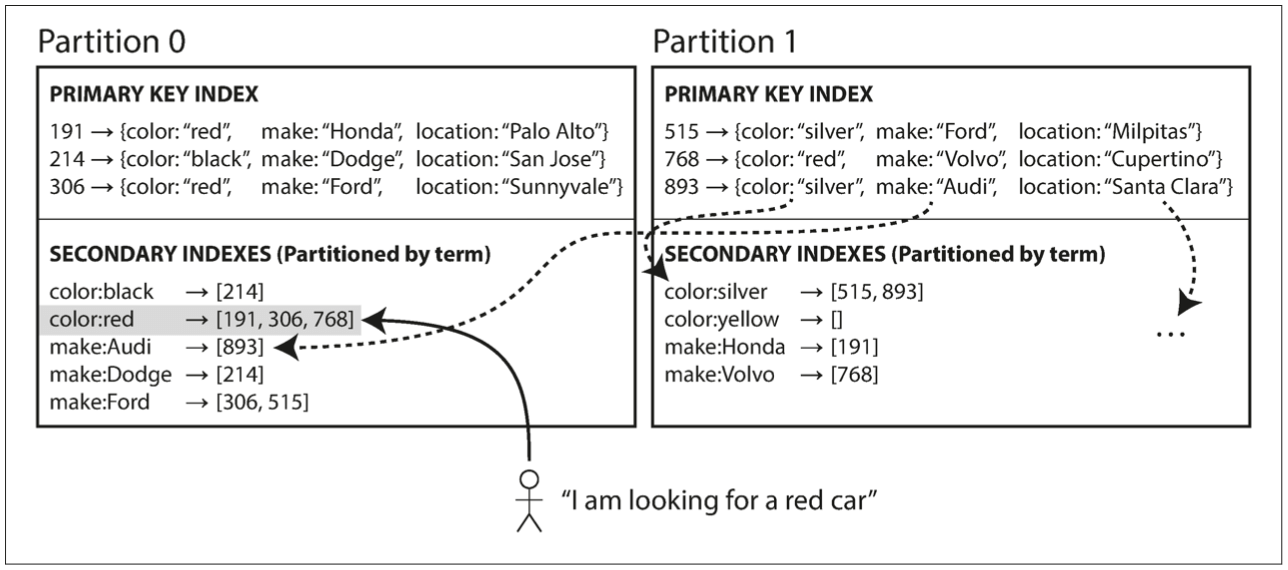
第二种方式是二级索引按照其他键分区,而不是主键。比如上图中颜色按照字典序分区,[a-r]在分区0中,[s-z]在分区1中。
这种方式的优点是查询二级索引不需要向所有分区发送请求,只要发到对应分区上就行了。
缺点是可能出现数据不一致,因为二级索引和主键可能不在同一个分区,添加新数据的时候需要向两个分区发送请求,一个是主键分区,另一个是二级索引分区,可能出现部分更新成功的情况,这需要分布式事务来解决这个问题。
分区再平衡
随着请求量的变化,分区的数量需要调整,请求量变多,分区数需要增加,请求量变少,分区数需要减少,这种调整叫做分区再平衡(partitioning rebalancing)。
分区再平衡可能会遇到下面几个问题:
-
再平衡后负载应该均匀分布。
-
再平衡移动的数据应该尽可能的少和快,减少不必要的数据移动。
-
再平衡过程中,服务器应该正常服务。
有两种再平衡方法。
固定数量分区
这种方式预先分配多个分区,分区数量比当前物理机器数量多不少,可以按照业务最大的负载数预估。比如10个物理机器可以分配1000个分区,每个物理机器负责100个分区。新增机器时,修改物理机器和分区的映射关系,新机器从每个旧机器上分配一些分区,修改的时候注意保持均匀分布。
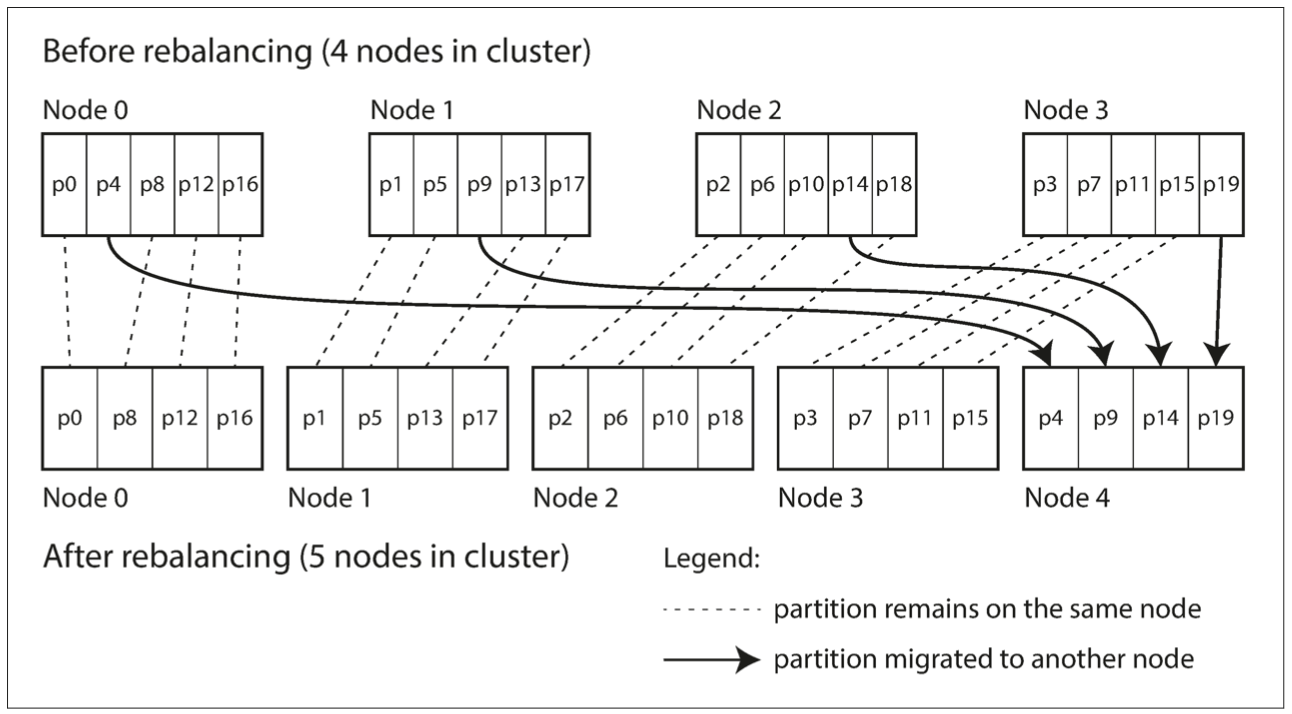
上图中一开始有4个物理机器,预先分配20个分区,每个机器负责5个分区。新加机器后,每个旧机器分配一个分区到新机器上,这样每个机器负责4个分区。
动态分区
另外一种方式是动态分区。这种方式不需要预先分配分区数量,而是动态计算分区。
一致性哈希也算动态分区的一种实现方式。
自动还是手动
再平衡应该自动处理还是手动处理?自动意思是程序自动检测是否需要再平衡,自动迁移分区到新的机器上。手动意思是管理员手动配置分区,手动发起再平衡流程。
两种方式各有利弊。纯自动可能会引起额外的问题。比如一个机器过载了,程序自动检测后发起再平衡流程,把数据从过载机器迁移到新机器,但是这个迁移过程会造成更大的开销,引起雪崩。纯手动的问题是容易配错。可以考虑折中一下,能自动的地方自动化,发起再平衡前再人工审核一下。
路由
分区后,客户端怎么知道数据在哪个分区,怎么把请求路由到正确的分区?有三种方式,如下图所示。
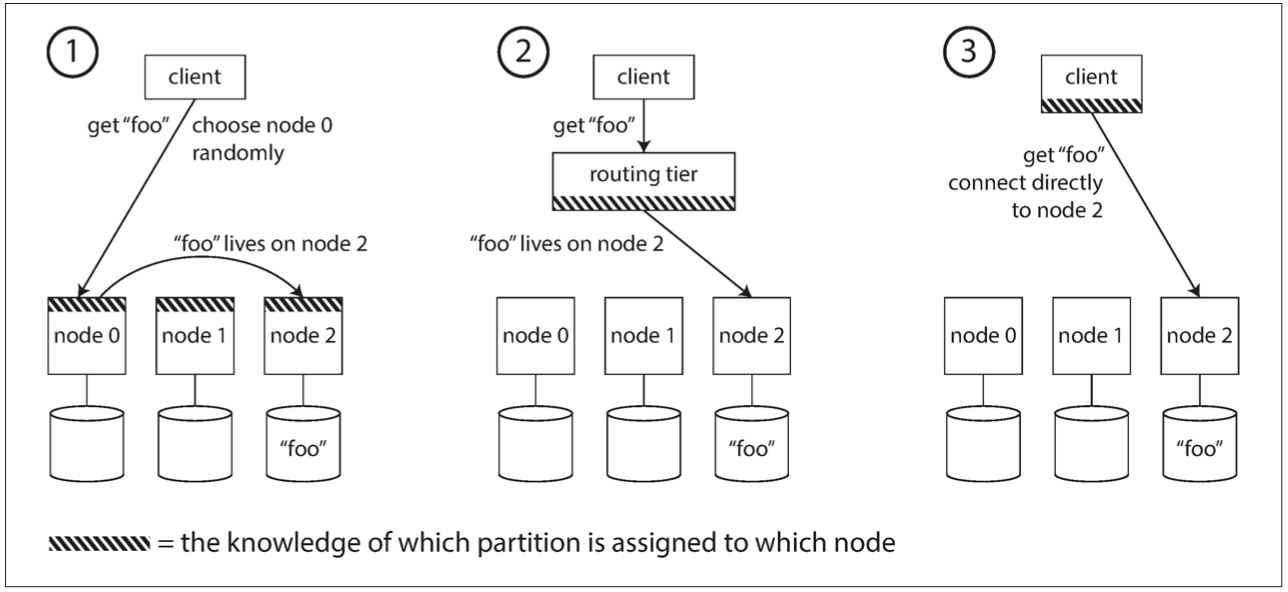
- 客户端随机找个节点,每个节点保存了当前的分区信息。如果这个节点刚好有对应数据,直接返回客户端,如果没有,把请求转发给对应的节点。
- 客户端把请求发给负载均衡服务器,这个服务器知道分区信息,转发请求给对应的节点。
- 客户端知道当前的分区信息,发请求到对应的服务器。
其中最大的挑战在于如何让每个节点都知道分区信息的变化,让所有节点产生共识(consensus)。一种方式是将分区信息放在ZooKeep上。但是如何实现?再平衡过程中如何保持服务的正常运行?如何保证数据迁移前后的一致性?数据迁移是一个比较麻烦的问题,有时间再专门研究。
参考
Designing Data-Intensive Applications