雪花算法(snowflake)是Twitter提出的一种在分布式系统中生成唯一ID的算法。格式如下:
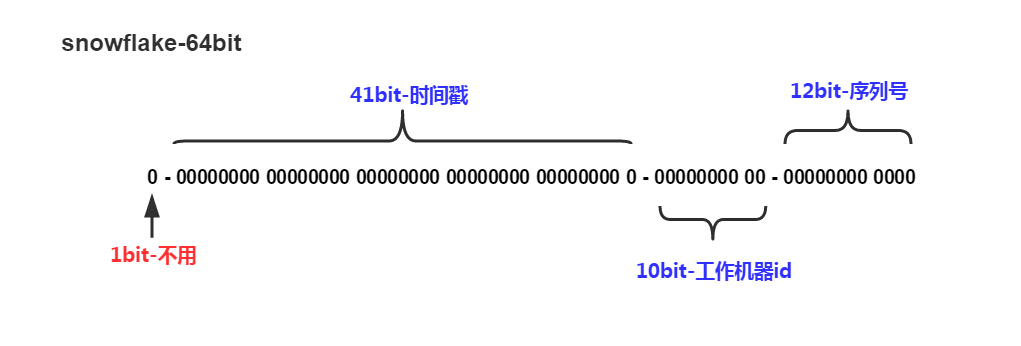
算法生成的是一个64位整型数字,由四部分组成:
- 首位始终填0。
- 接下来41位是从某个时间点开始计算的时间戳,单位为毫秒,可以不重复使用69年。
- 接下来10位是WorkerID,可以分配1024个节点。
- 最后12位是顺序增长的序列号,每个节点每毫秒可以生成4096个ID。
算法本身本身比较简单,优势在于:
- 不依赖于外部服务器,不需要额外的网络通信,实现简单
- 生成效率高
- 生成的ID总体有序增长
- 除首位外剩下三个部分的长度可以自由划分
虽然算法本身比较简单,但是有几个地方值得把玩一下,下面一一道来。
为什么首位始终是0
雪花算法生成的是64位整数,对于一些应用来说,比特占用情况是比较紧张的,为什么还要把首位始终设置为0不使用呢?这是因为Java中,所有整数都是有符号的。对于有符号数,首位为0表示正数,为1表示负数,所以需要把首位设置为0。当然,如果你的应用不需要考虑Java环境,这一位也可以正常使用。
三部分的位数如何划分
对于请求量不大的业务,时间戳部分可以不用毫秒为单位。根据业务情况可以在毫秒到秒之间取舍,比如10毫秒或者秒。
对于进程多的业务,10位WorkerID字段很可能不够用,需要从时间戳和序列号部分抠出一些比特来用。
WorkerID如何生成
本来以为这是一个很简单的问题,但一些环境却会使这个问题变复杂。
对于非云上业务,可以在本地配置文件中配置唯一的ServerID,进程启动时读取这个配置当作WorkerID来使用。
对于Kubernetes上的业务,会复杂一些。因为Kubernetes上的业务没有本地配置文件,需要想想其他的方案。
方案一:如果自己能控制Pod IP的分配方式,可以考虑使用IP的低16位或者若干位作为WokerID。前提是能够确保这些位不会有重复。
方案二:使用MySQL或者Redis的自增长字段来分配WorkerID。每次进程启动的时候,从MySQL或者Redis取一个增长的ID使用,因为只需要启动的时候和MySQL通信一次,之后一直使用这个ID,所以生成的性能不会受影响。如果业务重启不频繁的话,可以考虑这个方案。如果频繁的话,因为WorkerID的位数是有限的,比如10位是1024,16位是65536,也就是说只能重启1024次或者65536次。MySQL中的自增长ID超过这个最大值的话,只能循环从0开始,如果上一次分配的使用这个ID的进程还健在,就重复了,从而会造成使用雪花生成的唯一ID重复。那怎么办呢?
方案三:在MySQL中设置两个字段,一个字段是未分配的ID列表,另一个字段是已分配的ID列表。
- 预先在未分配列表中填充1024(10位WorkerID)个数字。
- 进程启动时从未分配ID列表中取一个ID,作为WorkerID,同时放到已分配ID列表中。
- 进程退出时,把ID从已分配列表删除,添加到未分配列表中。
这个方案需要注意不同进程并发获取ID造成的问题,可以考虑使用数据版本号等CAS方式来做到原子修改。
另外如果进程意外退出,那这个ID就不能回收到未分配列表中了。对于这个问题,如果池子中的ID足够多,可以不用考虑,毕竟进程不可能天天崩溃,ID够多的话足够应付很多年了。
方案四:MySQL中还是设置未分配ID列表和已分配ID列表,但使用租约机制,给已分配ID列表中每个ID添加一个时间戳表示这个ID的更新时间。进程启动获取这个ID后,需要定期到MySQL中更新这个ID的时间戳。如果进程意外退出,并且未分配ID列表中没有了可用ID,从已分配列表中找一个租约已经过期的ID使用。
方案五:增加ID分配服务器。但是这要考虑这个分配服务器的可用性问题,崩溃了怎么处理等。
系统时间回退怎么办
如果系统开了NTP网络对时协议的话,系统时间是有可能回退的,这会导致雪花算法生成的ID重复。所以一般系统会关闭NTP对时协议。但即使关闭了NTP对时协议,也可能遇到时间回退的情况,比如说闰秒。遇到这种情况,可以通过设置一到两位时间回拨位的方式解决,如下:

(图来自https://juejin.im/post/6844904035380658190)
算法中记录上一次生成的时间戳,发现有时间回退时,将时间回拨位加1,继续生成ID。这样虽然时间戳字段的值可能和之前的一样,但是回拨位的值不一样,生成的ID是不会重复的。如果系统的时间超过了上一次的回退时间后可以把回拨位归0。一位回拨位可以允许系统时间回退一次,两位回拨位可以允许系统时间连续回退三次。一般设置一位回拨位就够用了。
另外一种方案是获取一个新的WorkerID,这样WorkerID不会重复,生成出来的唯一ID也不会重复。
参考
Resolve Leap Second Issues in Red Hat Enterprise Linux
How to find out if the linux kernel will insert a leap second at the end of the month